Training Tesseract-OCR with custom data.
While trying to develop an OCR system for low-resolution images, I realized the shortcomings of the pre-trained tesseract models. For this reason, I decided to train it using my own data. Unfortunately, resources on how to do this on the internet are few and far between, and the ones you can find are not very detailed and are hard to understand for people with less experience. This is a detailed guide on how to set up the image files and train a custom tesseract model.
Steps involved:
- Gathering and naming image files.
- Generating Box files.
- Annotating Box files.
- Training Tesseract.
Gathering and naming image files.
The first task of finding all the image files that you want to use to train your custom model. This can be a full-page document or a single line of cropped text. The important part is to pick training images that accurately represent the data that your model is likely to receive. This way we can be sure that the model will produce accurate results after training.


After gathering these images, create a file structure as shown and place them in the data folder.

After gathering all the images, we need to rename them to a format that tesseract can understand.
[language name].[font name].exp[number].[file extension]
Generating Box files.
Once we gather the images, we can make tesseract generate box files for the text in the images. Tesseract will try its best to draw boxes around the characters and to identify them. This obviously won't be 100% accurate because otherwise, we wouldn't need to train tesseract.
This will produce a list of box files for each image file with the file format.[language name].[font name].exp[number].box
These box files will contain boxes around the characters in the image and what each character is.
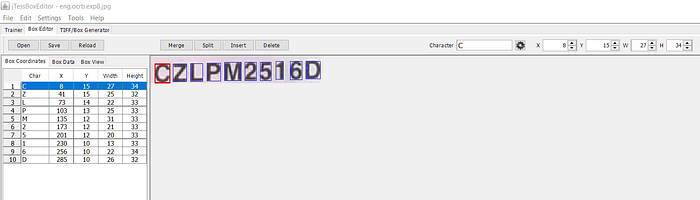
Annotating Box files.
Now comes the manual work of annotating the box files. We can use a program like jTessBoxEditor to open each image file and check the bounding boxes that tesseract has made. We can correct the boxes and the character in them. We can also add new boxes around characters that tesseract has missed.
This is the most important task as any mistakes will reduce the accuracy of the trained models.
Training Tesseract.
Once all the images have been annotated. We can start with the final training.
- First, we read all the box files and images and create a tuple.
2. For every image/boxfile in the list, we first check if train-data was generated for the image, if not we run
tesseract {srcdir}/{image} {destdir}/{image[:-4]} nobatch box.trainThis will create .tr files in the .trainfiles directory.
We also append the box file to the command.
unicharset_extractor — output_unicharset ../../{destdir}/unicharset
This command will later extract all the characters from all the box files and add them to a file called unicharset.
3. Once we generate train files. We write a file called font_properties.
Each line of the font_properties file is formatted as follows: fontname italic bold fixed serif fraktur.
where fontname is a string naming the font (no spaces allowed!), and italic, bold, fixed, serif and fraktur are all simple 0 or 1 flags indicating whether the font has the named property. Like ocrb 0 0 0 1 0
You can edit this file based on the font in your images.
4. Next we append all the files to the mftraining and cntraining commands and run them. This will give us a charset file for our language and 4 other files on the trainoutput directory.
5. Finally we can combine all the files into one .traineddata file. To use this copy the file to the tesseract source directory and use the -lang option to use the trained result. tesseract image.png -l [lang]
Note: Use purge file to remove all the train data and start from scratch.
